.svg)
Bell Curve in Performance Reviews: When It Fails and Smarter Alternatives
.svg)
0
min. read

Updated on:
January 16, 2026
Prefer Teamflect as your HR source on Google
.svg)
Summarize with ChatGPT
.svg)
The bell curve approach forces employee ratings into a predetermined distribution, assuming talent spreads naturally with most people in the middle. While intended to prevent rating inflation, this model ignores how modern networked work actually functions.
In reality, performance follows a power law: a small group of high-impact individuals drives a massive, disproportionate amount of value. By forcing a curve, companies squash these top achievers into "above average" boxes while overestimating underperformers.
Traditional calibration only worsens this, often replacing objective data with office politics and manager bias to maintain an artificial, symmetrical distribution.
The bell curve performance management system applies statistical normal distribution to employee performance ratings. This approach assumes that in any group, performance naturally spreads across a predictable pattern.
The core idea behind this model is forced distribution. Managers must place a fixed percentage of employees into each performance category, creating a curve that looks like a bell when graphed. This happens regardless of how the team actually performed.
Typical rating buckets follow a standard pattern:
Rankings get assigned through comparative evaluation rather than absolute performance. An employee might deliver strong results but still receive a middle rating because others performed even better. The system prioritizes relative ranking over individual achievement.
Leadership teams adopt the performance review bell curve for several specific reasons. Understanding these motivations helps explain why the model persists despite its documented problems.
When managers control their own ratings without constraints, grade inflation often occurs. Most employees end up rated as top performers, which defeats the purpose of performance differentiation. The bell curve forces managers to make harder choices.
Organizations want clear distinctions between employees for promotion and compensation decisions. The forced distribution method ensures that not everyone receives the same rating, creating a structured hierarchy.
Budget constraints require limiting top bonuses and raises to a percentage of the workforce. The bell curve in performance appraisal, for example, automatically identifies who receives premium rewards and who doesn't.
Different managers apply different standards when left to their own judgment. Some rate generously while others grade harshly. Performance rating distribution curves theoretically create consistency by imposing the same pattern everywhere.
The bell curve performance appraisal process involves several steps that transform individual manager assessments into a forced distribution. Each stage introduces specific risks to fairness and accuracy.
This process reveals a fundamental contradiction. Managers evaluate performance based on individual contributions and organizational context, but the system then discards those judgments to fit a predetermined pattern.
Performance calibration becomes a mathematical exercise rather than a genuine assessment of value delivered.
Most organizations using the performance rating bell curve follow similar percentage allocations. The specific labels vary, but the underlying structure remains consistent.
Some companies add a fourth or fifth category to create more granularity. A five-tier system might include "far exceeds," "exceeds," "meets," "partially meets," and "does not meet" expectations. The percentages adjust accordingly, but the principle stays the same.
The bell curve in performance management assumes these distributions reflect reality. In practice, actual performance patterns vary significantly by team, department, and time period. A team of carefully selected senior engineers will perform differently than a mixed group of new hires, yet the curve forces the same distribution on both.
The problems with forced ranking systems have been documented extensively through research and organizational experience. These issues affect both individuals and company performance.
When an entire group performs well, the system still requires labeling a percentage as underperformers. This creates perverse outcomes where excellent employees receive poor ratings simply because their teammates are exceptional.
Employees realize that helping colleagues succeed might push them down in relative ranking. This undermines knowledge sharing and collaborative problem-solving, particularly in roles where teamwork drives results.
The comparative evaluation model turns peers into competitors. When someone's gain becomes another's loss, people naturally protect their own standing rather than support team goals.
Employees who deliver strong results but receive middling ratings due to forced distribution feel the system is arbitrary. This damages trust in performance management processes and leadership judgment.
The bell curve in performance appraisal can rate someone who met all objectives as "needs improvement" because the curve required filling that bucket. Performance equity suffers when ratings don't match contributions.
High performers on strong teams often seek opportunities elsewhere when they realize the system will never recognize their full value. Organizations lose talented people who would thrive in environments using different evaluation methods.
Supervisors who understand their team's performance can't act on that knowledge when the distribution is predetermined. This reduces accountability and makes the review process feel bureaucratic rather than developmental.
The assumption of normal distribution doesn't match reality for many roles. Specialized teams, small groups, or units with unique selection criteria don't fit the bell curve model's statistical assumptions.
The shift away from forced ranking reflects fundamental changes in how organizations think about talent development and performance measurement.
Modern performance management software like Teamflect supports this evolution by enabling continuous feedback, goal tracking, and calibration discussions without forcing artificial distributions.
Teamflect’s Microsoft Teams integration makes ongoing coaching conversations part of daily work rather than annual exercises.

Despite its significant flaws, forced distribution can work in limited circumstances. These situations are rare and require specific organizational conditions.
Even in these cases, the disadvantages of using the bell curve in performance appraisal remain. Organizations should limit its use to specific scenarios and pair it with other assessment methods that capture individual context and organizational goals.
Replacing forced distribution with more effective approaches requires rethinking how performance gets measured and discussed. Several models have proven more successful at driving actual performance improvement.
Employees get evaluated against specific objectives they helped set at the period's start. Ratings reflect achievement levels rather than comparison to peers. This approach maintains differentiation without artificial constraints.
Regular coaching conversations replace annual rankings. Managers provide real-time input on both strengths and development areas. Performance evaluation software like Teamflect makes this sustainable by building feedback into existing workflows.
Objectives and Key Results create transparent, measurable targets. Performance assessments examine progress against these commitments. Everyone knows what success looks like before the evaluation period begins.
Organizations define skills and behaviors required for each role. Reviews measure demonstrated competencies rather than rank-ordering people. This supports talent development by identifying specific growth areas.
Evaluation focuses on delivered results and impact. Teams working on different initiatives get assessed against their specific contributions. This works well for knowledge work where outputs vary significantly.
In 360-Degree Feedback, input comes from peers, direct reports, and cross-functional partners in addition to managers. Multiple perspectives reduce manager subjectivity and provide richer developmental insights.
Managers discuss ratings in groups to ensure consistency, but without predetermined percentage requirements. This maintains fairness while respecting actual performance patterns.

Teamflect enables organizations to move past bell curve limitations through features designed for contemporary performance management needs. The platform supports fair, development-focused evaluations without forced ranking.
Teamflect proves that performance management can maintain high standards and clear differentiation without the disadvantages of bell curve in performance appraisal. Organizations get better data and employees get fairer treatment.
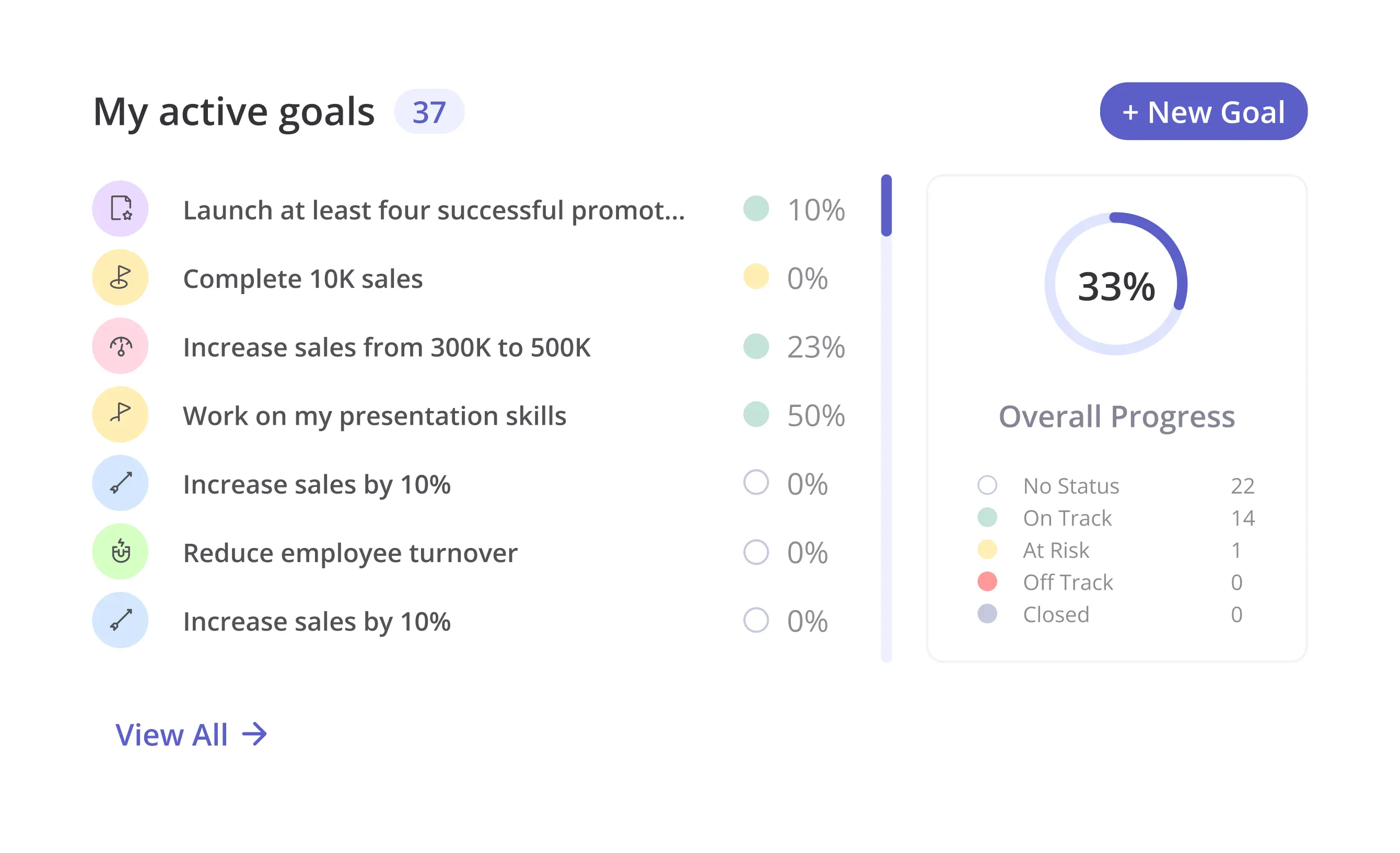
Some organizations continue using forced distribution, but adoption has declined significantly. Most companies have moved to goal-based or continuous feedback models that don't require predetermined performance rating distribution. The shift accelerated after high-profile companies like Microsoft abandoned the approach and reported better outcomes.
The system feels arbitrary when strong performers receive middling ratings because teammates performed even better. Employees see the disconnect between their actual contributions and forced rankings. The comparative evaluation model also damages collaboration by creating zero-sum competition for limited top ratings.
Research shows minimal performance improvement from forced ranking systems. The model can increase short-term differentiation but often harms long-term results through reduced collaboration and higher attrition. Organizations using alternative approaches typically report better talent development and stronger team performance.
Yes, particularly among high performers on strong teams. When capable employees receive ratings below their contribution level due to forced distribution, they often leave for organizations with fairer systems. The review inflation that forced ranking aims to prevent is less costly than losing talented people who feel undervalued.
Forced distribution is generally legal, but implementation must avoid discrimination. If the system disproportionately impacts protected groups or lacks clear job-related criteria, it could create legal risk.
Organizations should document how performance rating distribution decisions connect to legitimate business needs and ensure consistent application across all groups.

.svg)
.avif)
Create high-performing and engaged teams - even when people are remote - with our easy-to-use toolkit built for Microsoft Teams

.webp)