.svg)
Competency Mapping for Performance Reviews: How to Connect Skills to Evaluations
.svg)
0
min. read

Updated on:
May 8, 2026
Prefer Teamflect as your HR source on Google
.svg)
Summarize with ChatGPT
.svg)
When done right, competency mapping can fix some of the most common problems organizations of all sizes run into with performance reviews. After seeing countless teams struggle and ask our internal HR experts about this, we decided to put together the ultimate guide for integrating competencies into performance appraisals
Every performance review cycle produces the same complaint from HR teams that already have a competency framework in place. Managers don't know what to write in the behavioral fields. Ratings for the same competency land two or three points apart across comparable employees. The data that comes back can't support any decision that requires comparing one person to another.
According to Gallup's recent Re-engineering Performance Management report, only 2% of CHROs say their performance systems are effective, and only 26% of employees say their reviews are accurate. A framework that never reaches the review form is one of the recurring reasons why.
This guide is for HR leaders and People Ops managers who have done the framework work and need to operationalize it inside the evaluation workflow itself.
Most teams that ask for help with competency mapping already have a framework in place. The framework names what the company values: collaboration, customer focus, strategic thinking, ownership.
Mapping is the work that comes after defining needs & values, and it's the work most companies skip.
Building a competency framework identifies what matters. Mapping connects those competencies to specific roles and review criteria, with a shared rating standard everyone scores against.
The most useful answer to "what is competency mapping" is operational rather than definitional: it's the process of taking the competencies in your competency models and frameworks and turning them into the actual structure of your performance review.
Operational mapping rests on three components:
When all three are in place, the performance review competencies on the form line up with the work each role actually does. The rating scale carries shared meaning across teams.
When any one is missing, the framework stays in SharePoint and review forms keep producing the rating spread that has HR scratching its head every cycle.
When HR teams come to us frustrated that their competency framework isn't producing useful review data, the failure pattern is almost always one of three things, often all three at once.
Most competency frameworks are built at the org level. Strategic thinking, customer focus, ownership, collaboration. The framework lists each one with a generic definition and ships it to every role in the company.
"If I rate you on strategic thinking, over 60% of my rating reflects me and not you."
— Marcus Buckingham: Nine Lies About Work
The problem shows up the moment a manager has to rate someone:
When the competency definition is generic, every manager has to silently translate it into something that fits their team. That translation happens in the manager's head, never on the page, and it's different from one manager to the next.
The data that comes back from the cycle isn't really comparable. No two managers were rating against the same definition.
The second failure is mechanical. The framework lives in one place, the review form lives in another, and the work of bridging them falls on the manager.
The pattern is so common it's almost a cliché. The competency framework is a 40-page PDF in SharePoint or a Notion page that took six months to write. The review form is a separate tool, sometimes a built-in HRIS module, sometimes a spreadsheet template HR sends out before each cycle. The two systems don't know about each other.
To rate "strategic thinking," a manager would have to open the framework PDF, find the right competency, read the definition, then return to the review form and translate that into a score.
What happens instead:
The third failure shows up after the reviews are submitted. As SHRM Labs noted in its 2024 piece "Fixing Performance Reviews, for Good," calibration sessions are supposed to create consistency across the organization.
Without behavioral anchors at each rating level, "meets expectations" means whatever the rating manager privately thinks it should mean. Academic research cited in that same SHRM piece suggests more than 60% of a performance rating can be attributed solely to the idiosyncrasies of the manager doing the rating.
A framework defined too abstractly to be specific to any role makes the workflow gap harder to bridge, and a workflow without behavioral anchors guarantees the performance review calibration process will run on advocacy instead of evidence.
Solving any one of them in isolation rarely fixes the cycle. The next section walks through the operational fixes for each, starting with the abstraction problem at its root.
This is the operational core of competency mapping. The process has three stages: grouping roles into families, writing behavioral indicators at each proficiency level, and connecting each competency to a specific section in the review form.
The instinct most HR teams have is to start with the org chart and map at the job-title level. Sales Manager. Senior Sales Manager. Director of Sales. Each gets its own competency set with its own behavioral descriptors.
This produces a framework that takes months to build and is out of date by the time it ships. Every reorg, new hire, or title change triggers another round of mapping. Most companies abandon the project halfway through.
Map at the role family level instead. A role family is a group of jobs that share the same core work, even when seniority differs:
Industry practice converges around 5 to 8 functional competencies per role family, with 10 to 20 being the workable upper limit. Beyond 20, calibration becomes impossible to do in a single session, and managers stop using the framework actively.
The benefit of role-family mapping is that proficiency levels do most of the work that title-level mapping was trying to do. A senior PM and an associate PM both get rated against "stakeholder management," but the associate PM is rated at the proficient level for their stage while the senior PM is rated at the advanced level.
Same competency, same behavioral anchors, different expected proficiency.
The framework stops being a 200-page document and becomes a single page per role family with rating criteria that scale.
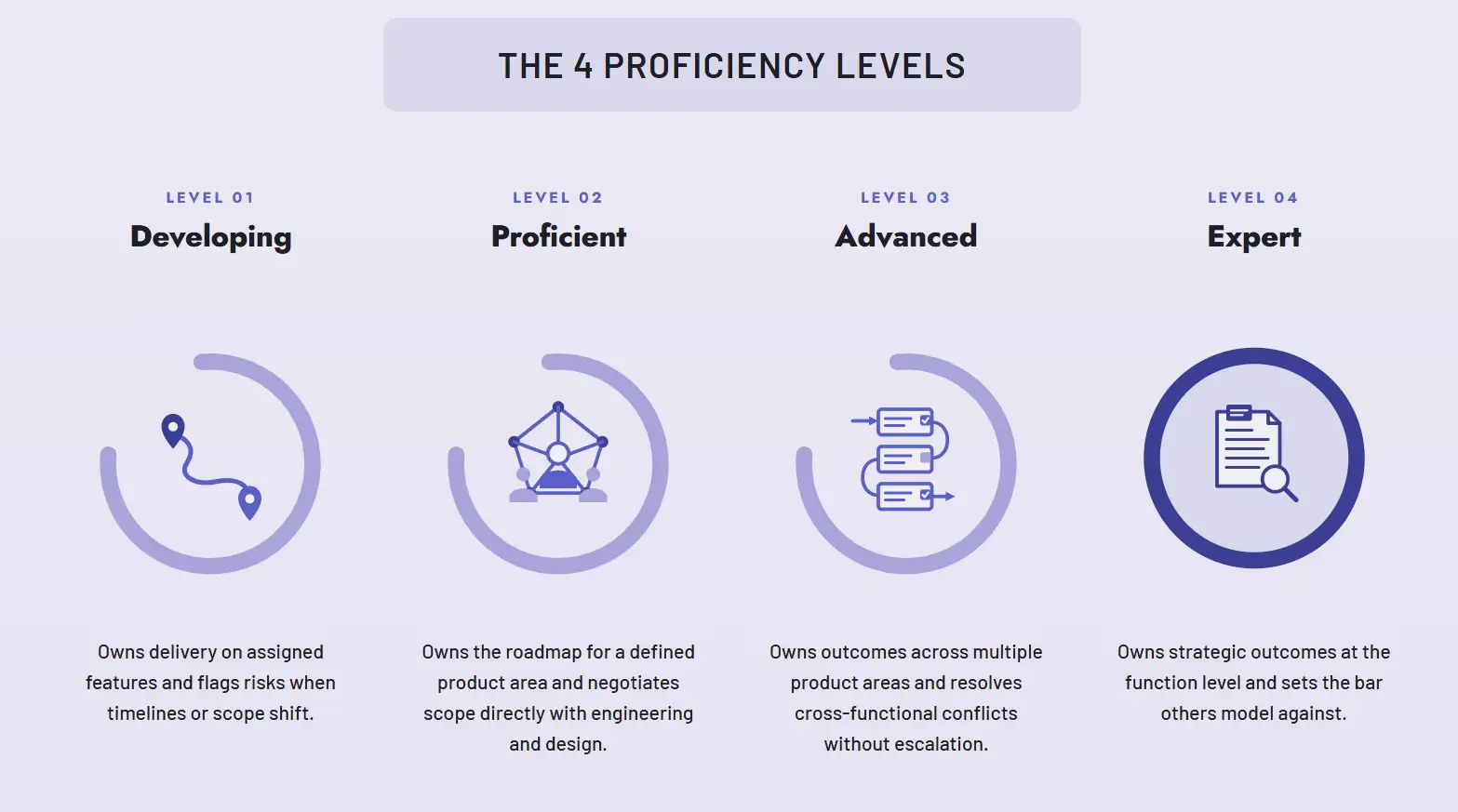
This is the work that turns the framework from abstract to operational. For each competency in a role family, define what the competency looks like at each proficiency level in observable terms.
A behavioral indicator is a specific action or output a manager can witness.
The standard test from organizational psychology is whether two managers, watching the same employee do the same work, would land on the same rating using the indicator alone. If the answer is no, the indicator is too vague.
Three to five proficiency levels is the standard range.
Most frameworks use four: developing, proficient, advanced, expert. Going beyond five tends to create distinctions managers can't reliably make. Going below three loses the ability to differentiate growth. The before-and-after on a single competency makes the difference visible. Take "ownership" for a product manager role family:
The Wrong Way to Define Competencies: Takes initiative and drives outcomes. Holds self and others accountable for results. Demonstrates a bias for action.
This is unrateable. A manager reading it has no way to distinguish a developing PM from an advanced one. The language describes a posture rather than an action.
The Correct Way to Define Competencies with Proficiency Levels & Behavioral Indicators:
A few drafting principles that hold up across role families:
Group similar incidents, abstract them into behavioral statements, and assign them to proficiency levels.
The mapping is only operational when it shows up in the review form itself. This is where most frameworks die.
The fix is structural. Each mapped competency should appear as a named section in the review form. The section header is the competency name. The behavioral anchors at each proficiency level appear directly under the rating field, visible at the moment the manager assigns the score.
The manager doesn't have to remember what "proficient" means or open another tab to look it up. The criteria are right there.
In practice, this looks like:
Once this structure is in place, the manager's job changes shape. Instead of staring at a blank text box trying to remember what the framework said about strategic thinking, they read the four behavioral anchors for the role family, watch them against what they've observed, and pick the one that matches.
What this produces, cycle over cycle, is rating data that's actually comparable across teams. A 3 in ownership for one employee means the same thing as a 3 in ownership for another employee in the same role with a different manager, because both managers were rating against the same behavioral anchor set.
That comparability is the precondition for any calibration session being productive, any compensation decision being defensible, and any talent review being grounded in something other than manager idiosyncrasy.
We built Teamflect's talent management tool, specifically to address all the needs and issues mentioned in this article. After our internal HR experts analyzed the growing need for HR departments to practice competency mapping and connect them to performance assessments, we built a module designed to do just that and more.
With customizable competency frameworks within Teamflect, you can easily map out every single role in your organization (Automatically drawn from Microsoft Entra ID) and allocate role levels and required competencies.
We highly recommend you adjust the weight of each competency for every role, building a truly tailored framework that represents your organization's reality.
With branching career paths, your employees can view their potential next roles, and the required competencies they need to achieve in order to be promoted.
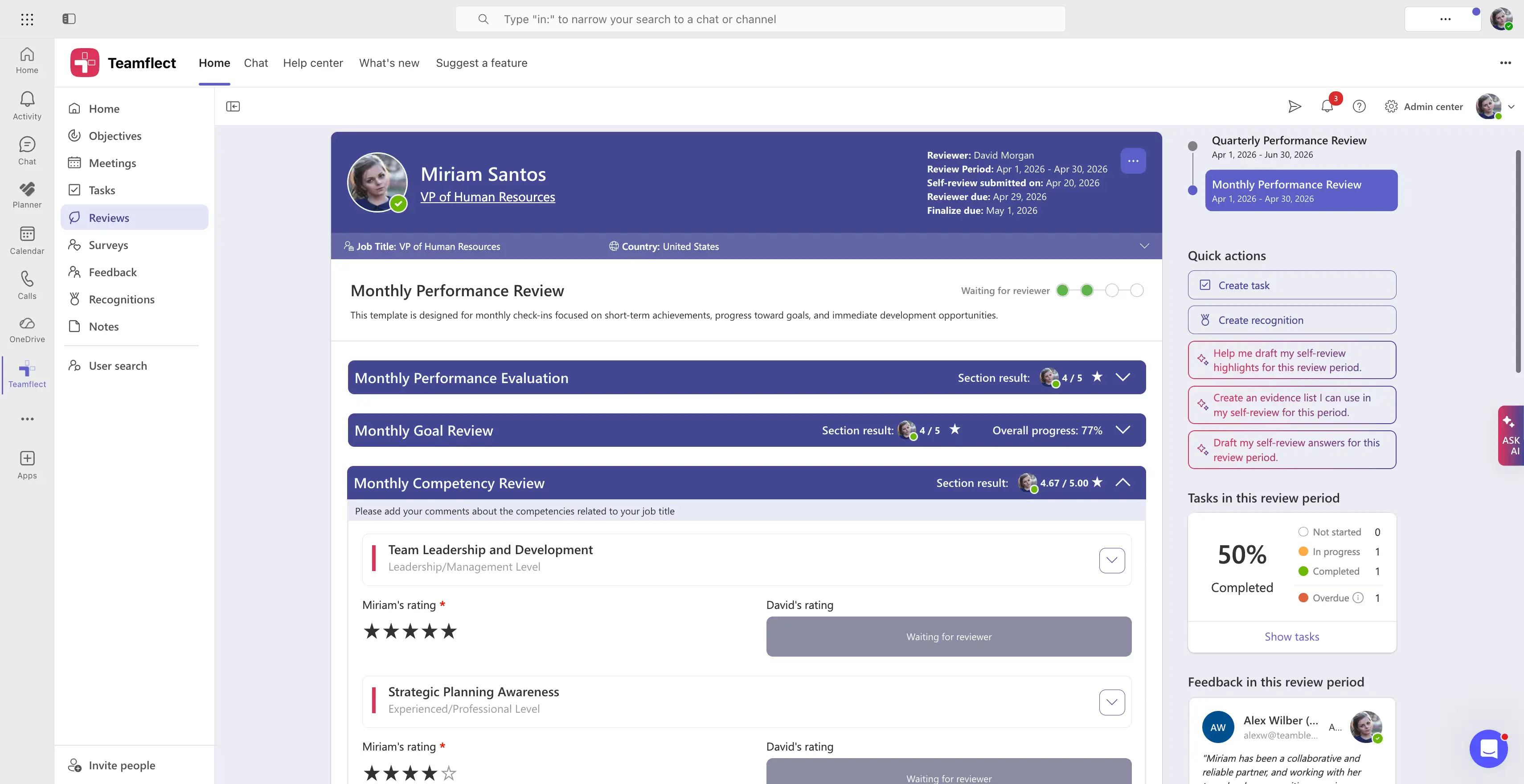
The next step to take after having the competency framework in place is to connect relevant competencies to performance reviews. Teamflect can do that automatically for users, if they choose to include a competency section in their performance review templates.
Competency questions inside performance evaluations can range from simple rating questions to open-ended ones. The most important part of this whole process however, is to track competency assessment results across reviews to get a clear picture of employee progress.
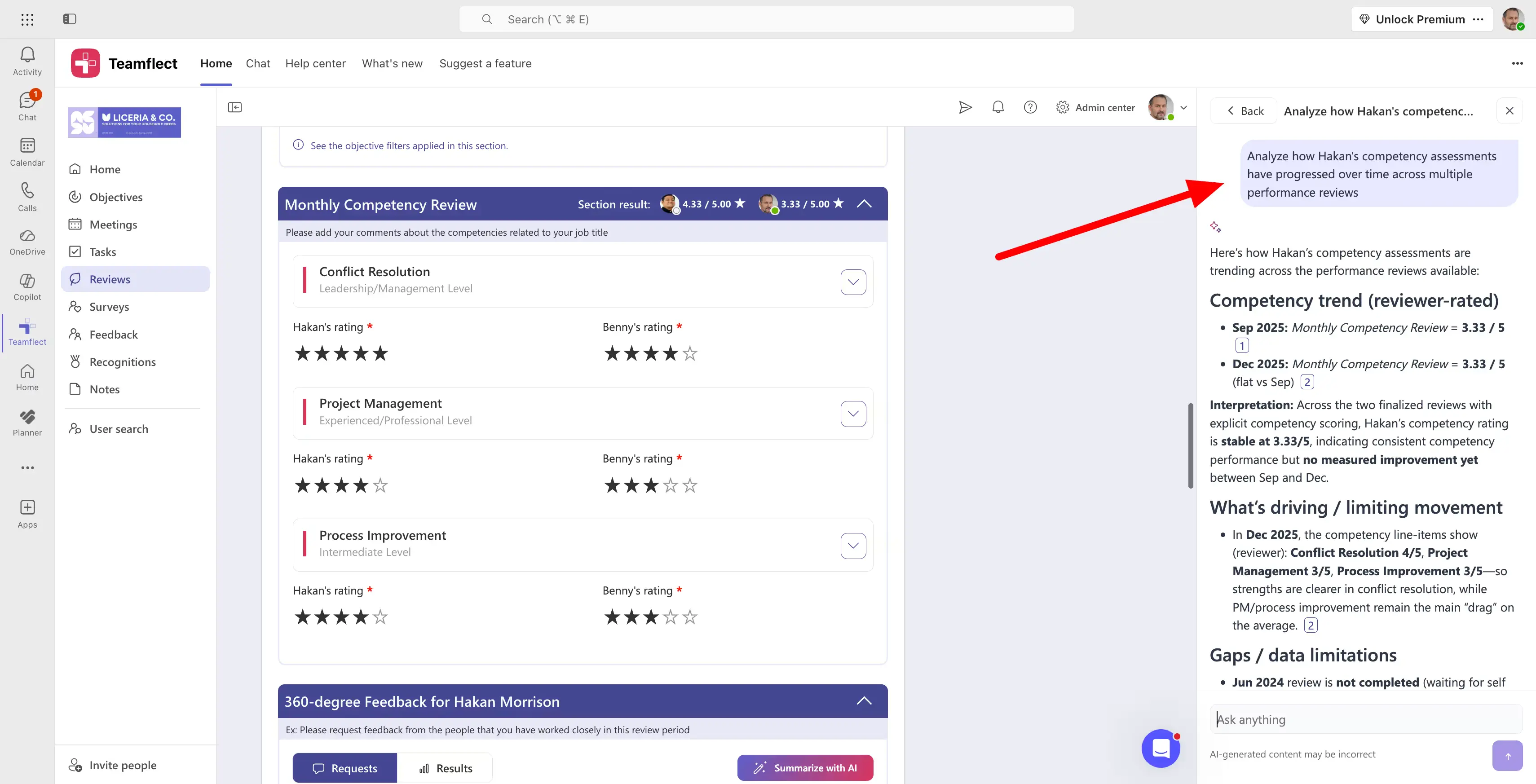
Analyzing trends in across various competency assessments is key. That is where the Teamflect Agent, an AI assistant built into the performance management platform, help. As seen in the image above, the manager can easily ask the agent to scan past reviews and bring forward how the employee's competency and skills evaluations have evolved over time. This is the perfect place to start building IDP's or succession plans from.
To learn more about how you can use Teamflect to integrate competencies into performance reviews inside Microsoft Teams, click the button below to schedule a demo.
The rating scale is where most competency frameworks fail in practice. Even when the role mapping is solid and the behavioral indicators are well-drafted, a poorly designed scale produces ratings that don't differentiate, don't calibrate, and don't support any decision the company needs to make.
Deloitte's 2024 Global Human Capital Trends survey found that 74% of respondents say finding better ways to measure performance beyond conventional metrics is critical, but only 17% report being very or extremely effective at it. The gap between knowing measurement matters and being able to do it well is largely a rating-scale problem.
The default rating scale in most HRIS modules is a 1-to-5 numeric scale with generic labels like "below expectations," "meets expectations," and "exceeds expectations." It's the path of the least resistance, and it's the wrong tool for competency-based evaluation.
Three failure modes show up in the data every cycle:
The deeper issue is structural. A numeric scale without behavioral content is asking managers to make a judgment and report it as a number, with no shared reference for what the number means.
The numbers look clean in a spreadsheet, but the underlying ratings are not. This is why common biases in performance reviews persist even in companies that invest heavily in rater training.
The alternative is to tie each point on the scale to a specific observable behavior. This is what behaviorally anchored rating scales do, and they've been in use since 1963, when Smith and Kendall first published the methodology.
The premise is that managers rate more consistently when they're matching observed behavior to written behavioral statements than when they're translating their judgment into a number on an undefined scale.
A BARS for "stakeholder management" in a product manager role family might look like this at two points:
A manager rating against this scale isn't asking themselves "is Sarah a 3 or a 4?" They're reading the behavioral anchor, watching it against what they've observed Sarah do, and selecting the one that matches.
The practical implication is to treat behavioral anchors as a structural improvement rather than a magic fix. They reduce the most common rating errors, they make calibration sessions productive, and they give employees concrete language for what they're being rated against. They don't eliminate bias, and there are deeper performance rating scales and competency assessment methods worth understanding before committing to a specific design.
The other failure mode in rating scale design is over-engineering. HR teams sometimes try to capture the complexity of human performance with eight or nine proficiency levels, half-point increments, or weighted dimensions within each competency. The result is a scale managers can't hold in their heads.
A few principles hold up across implementations:
The test for whether the scale is simple enough to use is whether a manager can summarize the proficiency criteria for one of their direct reports' competencies during an unscheduled conversation. If they have to open the framework to remember what "advanced collaboration" means, the scale is too complex or the anchors are too abstract.
The effect shows up across the entire talent management cycle, not just the review form. Four shifts, one per audience:

.svg)
.avif)
Create high-performing and engaged teams - even when people are remote - with our easy-to-use toolkit built for Microsoft Teams

.webp)